-
将压缩包上传到指定目录
-
解压缩
tar -zxvf Mycat-server-1.6.7.6-release-20220524173810-linux.tar.gz -
进入mycat/conf
-
配置server.xml

其中root为默认的用户信息,测试时可以使用当前账户,schemas为需要分库表的库名,需要配置多个schema用逗号隔开。defaultSchema 为默认的配置。可以看出server主要用来配置访问的用户,以及当前用户可以访问的库表 -
配置schemas.xml
-
首先配置Host

- name:节点主机名称
- maxCon:指定每个读写实例连接池的最大连接
- minCon:指定每个读写实例连接池的最小连接,即初始化连接池的大小
- balance:读操作负载均衡类型,目前有三个可选值”0”、”1”、”2”、”3”。读写分离相关策略,”0”代表不开启读写分离,读操作都发到writeHost上
- writeType:写操作负载均衡类型,目前有三可选值”0”、”1”、”2”,”0”表示所有写操作发送到第一个writeHost,第一个挂了切换到还生存的第二个writeHost。
- dbType:指定连接的数据库类型,目前支持二进制的Mysql协议,还有其他的JDBC连接的数据库。例如mongodb、oracle、spark等
- dbDriver:指定连接数据库的驱动,目前可选指为native和JDBC。native支持mysql和mariadb,其他数据库需要用JDBC驱动
- switchType:自动切换标识,”1”为默认值,表示不自动切换,其他可选指为”1”、”2”,
- tempReadHostAvailable:writeHost失联后,其下面的readHost仍旧可用,默认0,可选值0、1
-
配置writeHost 写库,参数为数据的基本参数,多个数据库配置多个dataHost
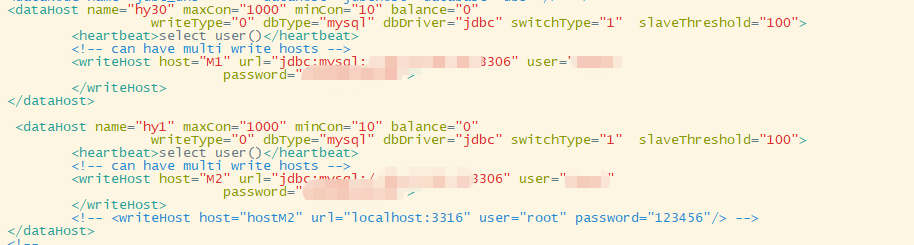
-
配置数据节点dataNode,有几个节点就需要配置几个

名称可以任意,datahost为上面配置的host的名称,database为对应的库名称 -
配置schema,先配置一个分片表进行测试

name数据库种对应的表名,dataNode为数据节点,rule为分片规则 -
对应数据结构

-
运行mycat
./bin/mycat console出现错误
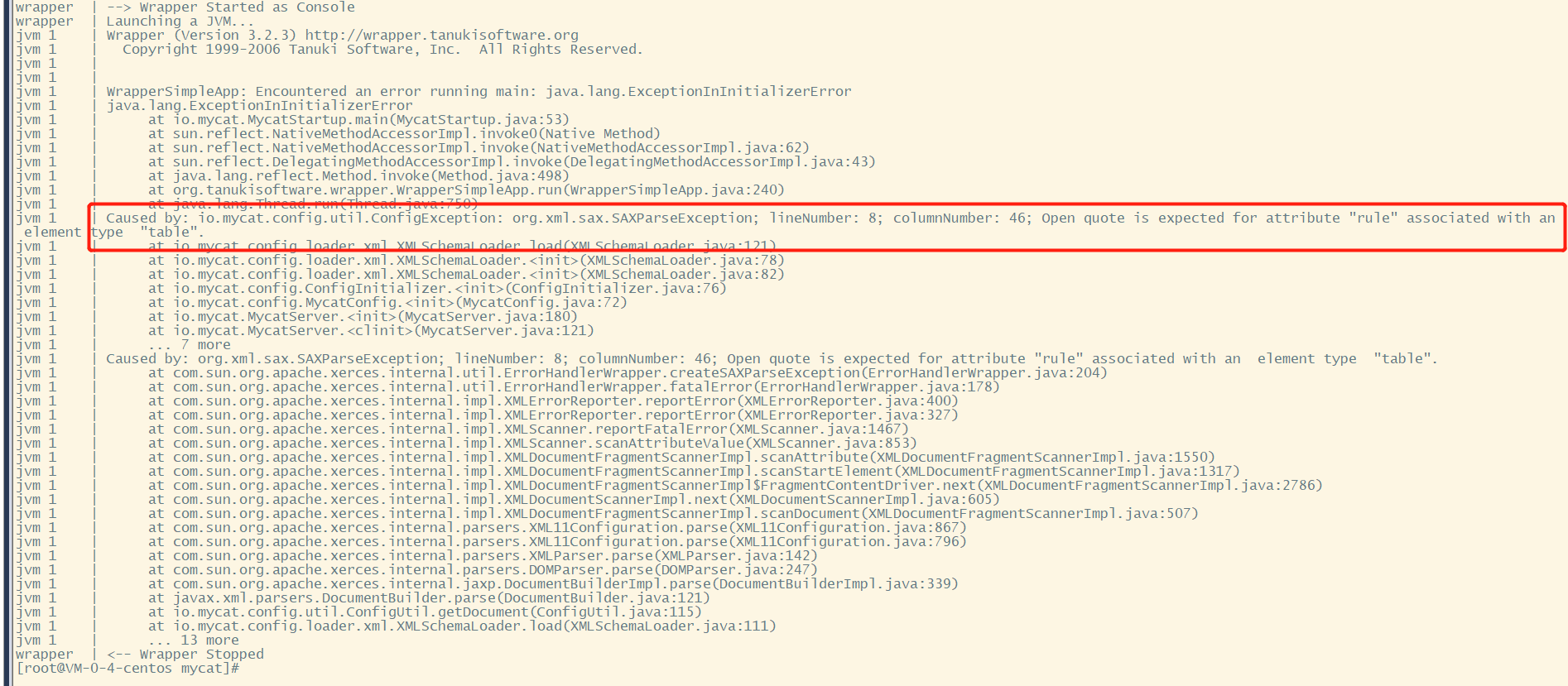
数据分片规则与node节点有问题,请确认 -
再次进入schemas.xml,可以看到配置的规则时auto-sharding-long
-
进入rule.xml,找到auto-sharding-long,看的规则为rang-long

-
往下在funciton中找到 rang-long

-
可以看的实现类和映射的文件为autopartition-long.txt,退出进入文件
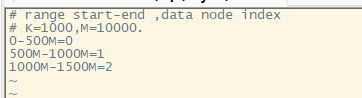
可以看到分片规则为每500M分配到一个库中,一共有三个分配规则,但是我们只有两个节点,当符合第三个分配规则的数据出现时,是不能分配的。 -
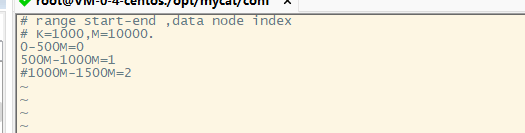
修改autopartition-long.txt,把最后一行注释
-
再次运行

出现root账户不存在错误, -
进入server.xml


配置的schemas为user,schemas.xml配置的是TESTDB,两者不一致,修改为一致,同时把user的schemas也改为user
-
再次运行,启动成功

-
使用navicat测试连接
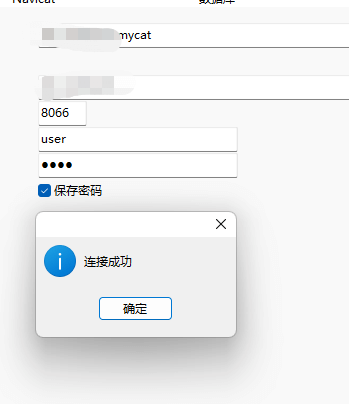
默认端口为8066,user账户和root账户连接都没有问题 -
进入user表
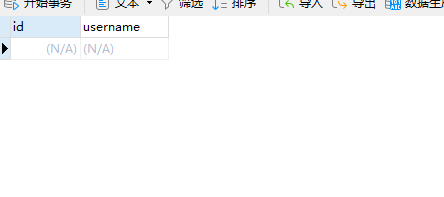
数据为空,添加一条id为1的数据
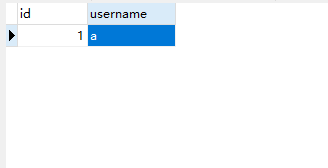
-
查看真实的数据库
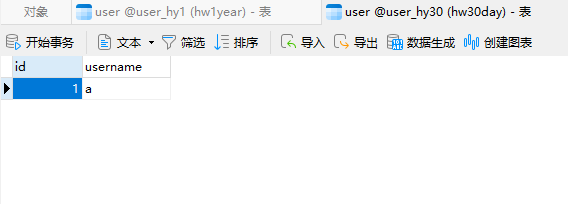

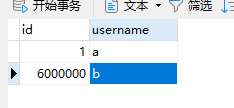
数据落在了30的库中,根据分片规则可以知道,1-500m的在30,500-1000m的在1y.然后我们创建一个id为6000000的数据进入
-
查看6000000的数据存储
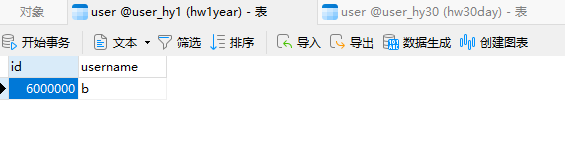
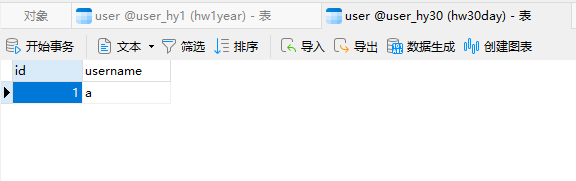
数据落在了1y的库中,分片成功