索引 index
对应到关系型数据中的概念,就是表,一个索引库就相当于一个表。
类型 type
相当于表的逻辑类型,ES7.0以后不存在了。
文档 document
相当于行,以json的形式存在
字段 fields
相当于列
stu在数据库中
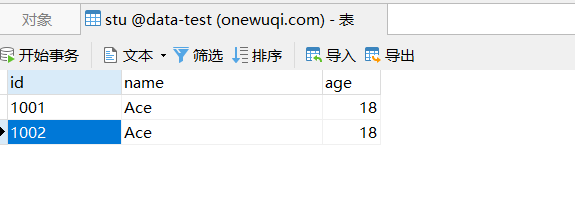
stu在es中

两个文档,就相当于在数据库中有2条记录
映射 mapping
表结构定义
近实时 NRT
Near real time ,当我们创建一个文档以后,用户要去搜索,这个搜索的延时,就被称为近实时。
节点 node
每一个服务器。es可以部署为集群,集群中的每一个服务器,就是一个节点
shard
把索引库拆分为多份,分别放在不同的节点上,比如有3个节点,3个节点的所有完整备份的索引库,分别保存到3个节点上,目的为了水平扩展,提高吞吐量
replica
每个shard的备份
ES集群架构原理
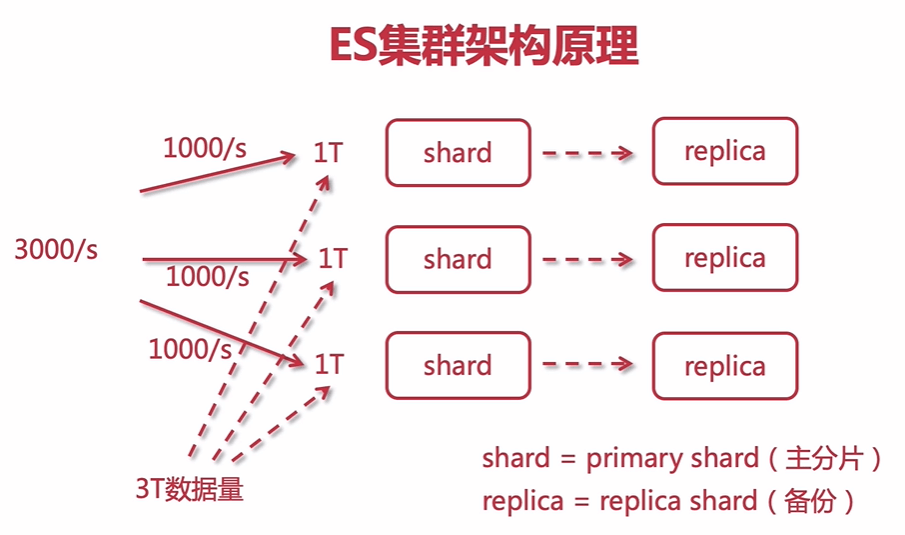
单个ES节点也是可以为用户服务的,一旦数据量庞大,单个节点可能服务不过来,因此可以增加节点来做集群以提高整个服务的吞吐量,(每个节点都有一个进程,每个进程都有一定的计算能力,多个节点并行计算就提供了吞吐量),为了防止节点崩溃,我们可以为每个节点准备一个备份分片来横向扩展,以提高每个节点的可用性,防止数据丢失。
倒排索引
倒排索引源于实际应用中需要根据属性的值来查找记录;
这种索引表中的每一项都包括一个属性和包含该属性值的各个记录地址;
由于不是根据记录来确定属性(key确定value),而是根据属性来确定记录的位置(value确定key)所以称之为倒排索引
首先看正排索引

就是在数据库中的一种存储,每一条记录都有一个id,按照一个顺序去排序,然后根据id既可以查询到对应的值
然后看倒排索引
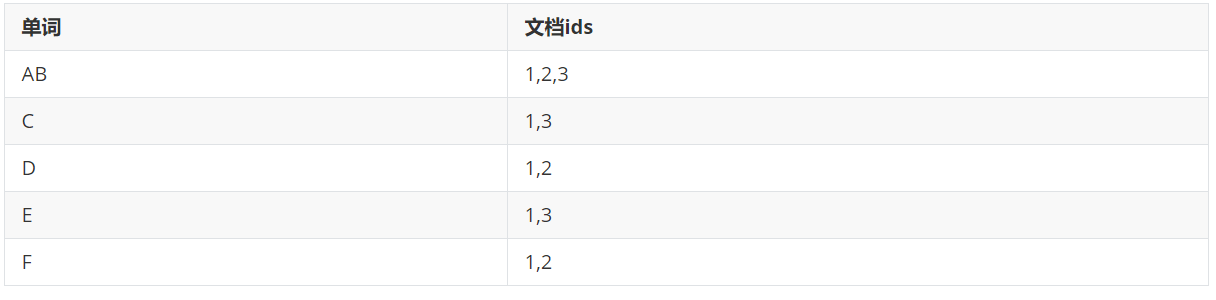
首先对内容进行一个分词,所有的内容都是从原本的内容中切分出来的,这样就可以把对应的单词出现的id进行归类,如果我们此时进行搜索,比如搜索AB,这时候发现1,2,3都包含AB,此时就会把结果都返回出来。
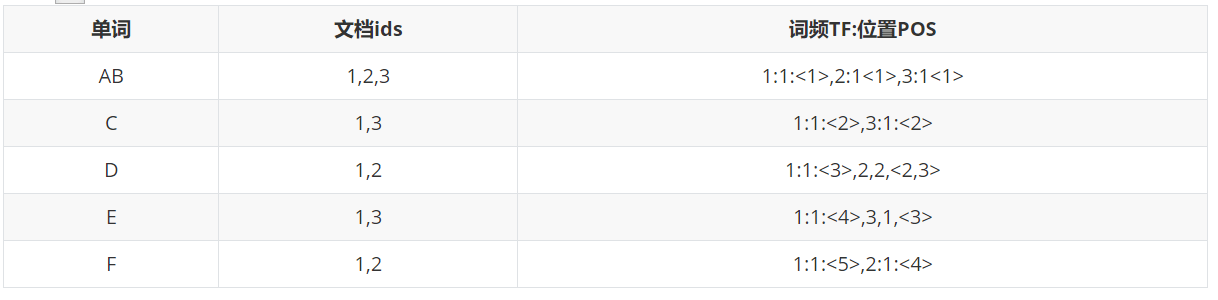
索引不仅能记录信息,还能记录单词出现的频率和位置,即出现重复的次数,比如AB,1:1:<1>(id:词频:位置),代表AB在id为1的数据中出现了一次,位置在第一位。